Проблемы голосовых технологий Обычно под этим термином подразумевают системы синтеза и распознавания речи, а совместное использование таких систем считают фундаментом полноценного голосового интерфейса. На практике сегодня часто используется односторонний голосовой интерфейс с подавляющим перевесом в сторону распознавания речи, притом что процесс распознавания сильно превосходит в сложности процесс синтеза речи.
Предпочтение распознаванию речи обусловлено насущными потребностями человеческой цивилизации, во многом стесненными природными особенностями коммуникативных функций человеческого организма. С одной стороны эти функции обеспечивают богатые возможности быстрого приема информации через зрительные и слуховые органы, с другой стороны выдача информации наружу возможна посредством вербальных органов (словесное общение) и значительно уступающих им в скорости средств неязыкового общения. "Общение" с механическими устройствами, аппаратурой и приборами в еще большей мере проявляет отставание в скорости неязыковых средств общения в сравнении с вербальным контактом. Так, например, нам быстрее отдать команду голосом, быстрее надиктовать текст, быстрее речью сообщить о своем решении, чем делать это руками при помощи элементов управления устройством. Конечно, не для всякого устройства подобное сравнение оправдано, однако наибольшее множество устройств управлялось бы прекраснее голосом.
Потому-то приоритетным оказывается развитие систем распознавания речи. И они развиваются, не всегда с тем успехом, как хотелось бы, но развиваются. Здесь нельзя безосновательно пенять на малый прогресс, ибо дело действительно сталкивается с существенными трудностями разного плана. Вот об этом мы и поговорим.
Прежде всего хотелось бы внести ясность в термины. Типично под распознаванием речи понимают весь комплекс услуг по трансформации речевого сигнала в завершенный и функциональный набор определяющих сведений о переданном сообщении. Но то, что сегодня используется в голосовом интерфейсе разных устройств, в принципе не является комплексом таких услуг. На самом деле часто речь идет о системе распознавания звуков, фонем или же определенных звуковых образцов в речевом сигнале. Истинным распознаванием речи следует называть симбиоз двух систем: распознавания звуков и понимания речи. Причем последняя весьма сложна и включает в себя массу высокотехнологичных решений, которые в свою очередь рождаются из новых теорий разложения, анализа речевых сообщений. Как следствие, многое зависит от того, что дает новая теория, какими предпосылками она связана, из чего исходит и куда ведет.
На словах процесс распознавания выглядит вполне понятно и просто. Однако на деле уже система распознавания звуков сталкивается с трудностями принципиального характера. Особенности голоса диктора (тембр, шумовые вкрапления, обусловленные строением речевого тракта), отличительные манеры проговаривания тех или иных звуков (ускорение или замедление темпа, "проглатывание" некоторых звуков, временное смещение тональности, тремоло затянутых гласных, неосознанная вставка незначащих призвуков между словами), специфичная артикуляция - все это накладывает отпечаток на спектральный состав речевого сигнала. А спектр, надо отметить, при таких условиях изменяется существенно, причем на его основе система распознавания звуков пытается отличить переходы звука в звук, и по этим причинам трудно сформировать универсальные эталоны звуков, сравнение с которыми не зависело бы от непредвиденных искажений в спектре. Кроме того, теории распознавания обычно базируются на аналогиях человеческой способности понимать речь, но нет ни одного способа реально увидеть или измерить, как это все работает внутри человека.
Быть может, тогда мы смогли бы внести в наши теории какую-то важную поправку, потому как мы легко понимаем, говори диктор хоть с хрипотцой, хоть старческим голосом, мужским, женским, детским, хоть через мегафон, радио, тихо, громко, хоть через разные искажающие фильтры - мы все одно понимаем. То есть для нас даже сильные искажения в спектре не являются барьером. Тут, конечно, нельзя забывать, что речь идет о сложной биологической конструкции, что анализ спектра может быть построен самым хитроумным образом, без всяких универсальных эталонов. И все-таки даже просто распознавание звуков человеком кажется на редкость поразительным, стабильно уверенным почти вне зависимости от окружающего шумового фона.
Дело даже не в фоне, а в способностях системы распознавания звуков. Когда мы попросим человека повторять за диктором какую-нибудь неспешно произносимую абракадабру, чтобы по возможности предельно исключить влияние системы понимания речи, то отметим, как человек легко распознает произносимую бессмыслицу, и характеристики речевого тракта диктора не оказывают существенного влияния на качество распознавания.
В этом как раз и проявляется то косвенное доказательство последних воззрений на способы реализации качественных систем распознавания звуков: создать такие системы можно, и принцип их функционирования не является непомерно сложным, только сегодня все тормозится проблемами технического характера. Воспринимающие рецепторные клетки уха выполняют мгновенное разложение звукового сигнала в спектр. Почти каждая рецепторная клетка реагирует на определенную частоту, а этих клеток там десятки тысяч. Аппаратное устройство с одним микропроцессором на такую же операцию - она называется дискретное преобразование Фурье - вынуждено будет потратить по самым скромным подсчетам около 20 тысяч тактов, если планируется отслеживать весь диапазон слышимых частот в пределах от 16 герц до 20 килогерц.
Как сегодня используется дискретное преобразование Фурье в системах распознавания звуков? Звук оцифровывают с какой-нибудь подходящей частотой, скажем 20 килогерц, то есть 20 тысяч раз в секунду измеряется мгновенное состояние звукового сигнала. Получается длинная цепочка дискретных замеров. Следует отметить, что почти всегда оцифрованный звук проходит предварительную обработку, в частности из него удаляются шумы и выполняется выделение только той полосы частот, которая содержит наиболее информативную составляющую речевого сигнала. Считается, что полоса частот до 4 килогерц в большинстве современных приложений достаточна, однако нужно также помнить, что чем уже выделяется полоса частот, тем больше огрубляются детали речевого сигнала, ответственные за перенос экспрессивных (выразительных) черт сообщения.
Далее устанавливается так называемый фрейм - это длина того кусочка звука, который мы хотим обрабатывать за один раз, соответственно звуковой сигнал обрабатывается кусочками. Для каждого кусочка применяется дискретное преобразование Фурье, которое выдает все частоты (амплитуды этих частот), из которых сформирован обработанный кусочек. Затем фрейм перемещается на некоторое расстояние вперед (обычно на размер самого фрейма) по звуковому сигналу, то есть мы переключаемся на обработку следующего кусочка. И так далее. Сравнивая амплитуды частот соседних кусочков, можно судить о том, какие изменения происходят в звуковом сигнале в конкретной точке времени. А эти изменения в разных полосах спектра нередко дают прямые указания на то, в какой фазе синтеза находятся сейчас органы речевого тракта диктора. Скажем, почти полное смещение активности в сторону средних частот спектра свидетельствует о том, что выполняется синтез звука, близкого к некоторым щелевым. Но и здесь уверенность в предсказании определяется тем, какова ширина активной полосы, ее огибающая форма, насыщенность и уровень активности.
Для пущей информативности приведем один из формальных алгоритмов работы линейной системы распознавания звуков, где речевой сигнал (допустим, с микрофона) обслуживается блоками определенного размера, зависящего от производительности устройства в целом.
Code
Размер_фрейма = сколько отсчетов анализировать за раз
Длина_буфера = Размер_фрейма * ЧИСЛО_ФРЕЙМОВ_В_БУФЕРЕ
выделить Память в размере Длина_буфера отсчетов
создать массив Частоты
создать массив Предыдущие_частоты
создать массив Нозальные_изменения
создать массив Щелевые_изменения
создать массив Смычные_изменения
создать массив ...и_так_далее_изменения
создать массив Цепочка_звуков
создать массив Цепочка_букв
загрузить базу Стационарные_образцы_изменений
загрузить базу Стабильные_фонемные_композиции
цикл поблочного приема речевого сигнала
Память = принять еще Длина_буфера отсчетов речи
подавить_шум(Память)
выделить_полосу_частот(Память, от ? Гц, до ? кГц)
Адрес_фрейма = адрес первого отсчета Память
Индекс = 0
цикл ЧИСЛО_ФРЕЙМОВ_В_БУФЕРЕ раз
Частоты = Фурье(Адрес_фрейма, Размер_фрейма)
сравнением Частоты и Предыдущие_частоты получить
текущие Нозальные_изменения[Индекс]
текущие Щелевые_изменения[Индекс]
текущие Смычные_изменения[Индекс]
текущие ...и_так_далее_изменения[Индекс]
конец сравнения
Адрес_фрейма = Адрес_фрейма + Размер_фрейма
Предыдущие_частоты = Частоты
Индекс = Индекс + 1
конец цикла
на основе последовательности сведений в массивах
..._изменения, и сравнивая их фрагментарно или же
с учетом возможных динамических временных факторов
со Стационарные_образцы_изменений, попытаться
заполнить Цепочка_звуков
из данных Цепочка_звуков и на базе сведений
Стабильные_фонемные_композиции попытаться
заполнить Цепочка_букв
конец цикла
Но преобразование Фурье обладает одним неудобным обстоятельством: для каждой частоты вычисляется ее средняя амплитуда на протяжении обработанного фрагмента исходных данных. Иначе говоря, если в начале фрейма какая-то частота была активна, а к концу фрейма сошла на нет, то преобразование Фурье просто укажет, что она была наполовину активна, то есть мы не сможем ничего узнать о действительном поведении частоты. В связи с этим немаловажное значение имеет не только размер самого обрабатываемого кусочка звука, но и то, насколько далеко вперед в следующем шаге обработки смещается фрейм. Наилучший вариант - ровно на один отсчет вперед, аналогично работе рецепторных клеток уха, что позволяет с ювелирной точностью следить за поведением частот спектра. Однако такой вариант для аппаратного устройства с одним микропроцессором ведет к падению производительности в то количество раз, чему равна частота дискретизации, то есть при 20 килогерцах производительность падает в 20 тысяч раз. Это слишком много для современной техники.
Теперь о том, что дает слежение за частотами. Разным фонемам присущи разные частотные узоры, причем здесь важно знать, что решающее значение имеют не чистые значения амплитуд частот узора, а их относительные характеристики между остальными частотами узора. Сливаясь, фонемы образуют объединенный узор. Точки сливания фонем трудны в анализе, поскольку в этих местах невозможно без специальных ухищрений адекватно судить о том, какие фонемы смешаны, а то и вовсе бесполезно это делать. Но и существуют доминирующие места, где фонема проявляется почти в чистом виде (хотя это вовсе не значит, что там фонема окажется похожей на свой среднестатистический эталон). Вот эти точки и являются опорными. По ним хотя бы на первых порах оценивается чередование гласных и согласных звуков. Одновременный контроль в разных полосах спектра обеспечивает более точную оценку не только чередующихся звуков, но и соотнесение их с методом синтеза.
Впрочем, и тут возникает конфликт предпочтений и необходимостей. Всегда есть желание привязаться к абсолютным измерениям и эталонам, в то же время явно просматривается требование относительных сравнений, так сказать безразмерных эталонов, фиксированных на резонансных частотах, чтобы притом эталоны легко передвигались вдоль линии частот и не осекались бы на слившихся с текущей фонемой частотах соседней фонемы. Пожалуй, яснее взгляд на современные теоретические новации в области распознавания звуков станет, если изобразим при помощи сонограммы фрагмент речевого обращения, например, с текстом "понятно чего ожидать".
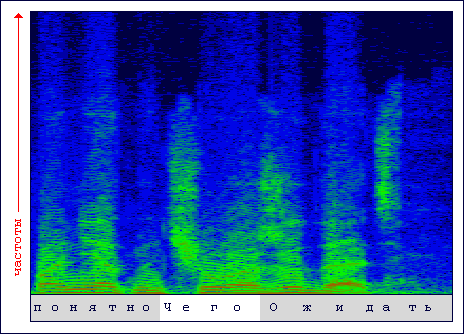
Сонограмма в большей мере демонстрирует результат слышимости частот ухом на протяжении звучавшего фрагмента. Сложенная из тонких вертикальных полос, цвет точек которых означает мгновенную активность разных частот (снизу вверх от низких частот к высоким), она как бы иллюстрирует пошаговое продвижение фрейма с минимальным размером шага. Конечно, размер самого фрейма позволяет охватить больше или меньше частот, но в первом случае расплачиваться приходится усиленным проникновением частот соседних фонем. В общем, баланс разумного соотношения размера фрейма и его шага сегодня осуществляется методом "научного тыка". Сказывается все-таки и нехватка производительности, отчего эксперимент слабо помогает развитию новых теорий, сказывается и сама ограниченность теорий, обусловленная потребностью постижения вещей, которые трудно осваиваются умозрительно, не говоря уж о системах понимания речи, где вообще невозможно адекватно осмыслить речевое сообщение, включая его экспрессивные характеристики, без привлечения элементов искусственного интеллекта.
Так что нынешний день пока не готовит нам свидание с полноценными голосовыми интерфейсами. Но дело не стоит на месте, шаг за шагом люди идут к желанной цели. Уже есть работающие голосовые системы, неповоротливые, но все же пригодные в узком круге задач. Бывает, после значительных усилий высококлассной команды специалистов наступает неожиданный качественный скачок, например как это произошло в области синтеза голоса. Да, синтез и в этом случае осуществляется не без предварительного и определяющего участия человека. И все-таки... раньше даже такое казалось просто фантастикой. Рекомендуется зайти на сайт разработчика сей штуки и послушать демонстрационные файлы, весьма впечатляет. А вот с распознаванием речи дела обстоят похуже. Хотя и здесь нельзя сказать, что топчемся на месте. Просто всему свое время. Наступит и тот день, когда все трудности будут решены, когда неуклюжий голосовой интерфейс станет делом давно минувших дней.






